IFN for Classification of Data Table (Supervised Learning)
Ideal Flow Network (IFN) can be used for Machine Learning, Data Science and Artificial Intelligence.
Classification is a type of supervised learning where the algorithm is trained on labeled data to predict the output. The goal of classification is to assign a class label to a new, unseen instance based on the patterns.
In this tutorial, you can see how we can use IFN for Classification of data table. I demonstrate below that IFN can be also used as Generative AI.
First, you need to import the modules for this tutorial.
[1]:
import IdealFlow.Table as ift # import package.module as alias
import random
import os
Data Preparation
In this tutorial we are going to use the following textbook data table.
Here is the agreement of the format of data table:
In the first row, the data table contains the variable name. The last column must be the category or class label.
From the second row onward, the data table contains the values for each variable. Only one value per variable is allowed.
The number of rows and The number of columns are only restricted by your memory.
[2]:
table_data = [['Give Birth', 'Lay Eggs', 'Can Fly', 'Live in Water', 'Have Legs', 'Class'],
['yes', 'no', 'no', 'no', 'yes', 'mammals'],
['no', 'yes', 'no', 'no', 'no', 'non-mammals'],
['no', 'yes', 'no', 'yes', 'no', 'non-mammals'],
['yes', 'no', 'no', 'yes', 'no', 'mammals'],
['no', 'yes', 'no', 'sometimes', 'yes', 'non-mammals'],
['no', 'yes', 'no', 'no', 'yes', 'non-mammals'],
['yes', 'no', 'yes', 'no', 'yes', 'mammals'],
['no', 'yes', 'yes', 'no', 'yes', 'non-mammals'],
['yes', 'no', 'no', 'no', 'yes', 'mammals'],
['yes', 'no', 'no', 'yes', 'no', 'non-mammals'],
['no', 'yes', 'no', 'sometimes', 'yes', 'non-mammals'],
['no', 'yes','no', 'sometimes', 'yes', 'non-mammals'],
['yes', 'no', 'no', 'no', 'yes', 'mammals'],
['no', 'yes', 'no', 'yes', 'no', 'non-mammals'],
['no', 'yes', 'no', 'sometimes', 'yes', 'non-mammals'],
['no', 'yes', 'no', 'no', 'yes', 'non-mammals'],
['no', 'yes', 'no', 'no' ,'yes', 'mammals'],
['no', 'yes', 'yes', 'no','yes', 'non-mammals'],
['yes', 'no', 'no', 'yes', 'no', 'mammals'],
['no', 'yes', 'yes', 'no', 'yes', 'non-mammals']]
table_data
[2]:
[['Give Birth', 'Lay Eggs', 'Can Fly', 'Live in Water', 'Have Legs', 'Class'],
['yes', 'no', 'no', 'no', 'yes', 'mammals'],
['no', 'yes', 'no', 'no', 'no', 'non-mammals'],
['no', 'yes', 'no', 'yes', 'no', 'non-mammals'],
['yes', 'no', 'no', 'yes', 'no', 'mammals'],
['no', 'yes', 'no', 'sometimes', 'yes', 'non-mammals'],
['no', 'yes', 'no', 'no', 'yes', 'non-mammals'],
['yes', 'no', 'yes', 'no', 'yes', 'mammals'],
['no', 'yes', 'yes', 'no', 'yes', 'non-mammals'],
['yes', 'no', 'no', 'no', 'yes', 'mammals'],
['yes', 'no', 'no', 'yes', 'no', 'non-mammals'],
['no', 'yes', 'no', 'sometimes', 'yes', 'non-mammals'],
['no', 'yes', 'no', 'sometimes', 'yes', 'non-mammals'],
['yes', 'no', 'no', 'no', 'yes', 'mammals'],
['no', 'yes', 'no', 'yes', 'no', 'non-mammals'],
['no', 'yes', 'no', 'sometimes', 'yes', 'non-mammals'],
['no', 'yes', 'no', 'no', 'yes', 'non-mammals'],
['no', 'yes', 'no', 'no', 'yes', 'mammals'],
['no', 'yes', 'yes', 'no', 'yes', 'non-mammals'],
['yes', 'no', 'no', 'yes', 'no', 'mammals'],
['no', 'yes', 'yes', 'no', 'yes', 'non-mammals']]
Having the data table, now we can
define the class by specifying the model parameter and name of this task
prepare the data for IFN Classification. The prepare_data_table method would split the data table into the input (X) and output (y).
Then, we can train the data into the model to calbrate the model and it would produce the accuracy.
Optionally, you can show the IFN for each category label
Next, you can predict the category label for the data
You can also generate back the input for the given category label
Thus, IFN is also AI generative model.
[3]:
# define the class
tp = ift.Table_Classifier(markovOrder=2,name="Mammal Classification")
# define the input (X) and output (y) from data table
X, y = tp.prepare_data_table(table_data)
# train the IFN model
accuracy = tp.fit(X, y)
print("Accuracy:", accuracy)
# show the IFN for each category label
for name,ifn in tp.IFNs.items():
print(name,':',ifn)
ifn.show(layout="Circular")
# predict the category label
print("\nprediction =",tp.predict_table(X),'\n','\ntrue y =',y,'\n')
# generate the input
category=random.choice(y)
tr=tp.generate(category)
print('trajectory for',category,":\n",tr)
Accuracy: 0.9
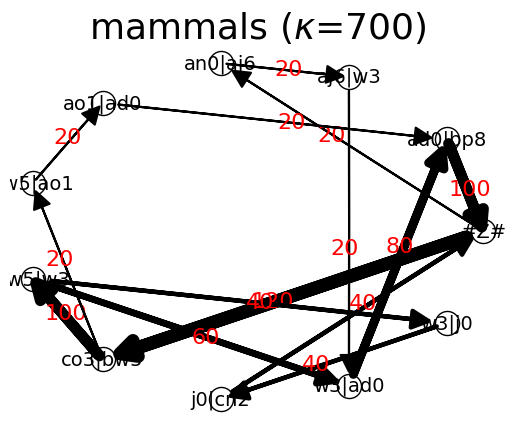
mammals : {'#Z#': {'co3|bw5': 120, 'an0|aj6': 20}, 'co3|bw5': {'bw5|w3': 100, 'bw5|ao1': 20}, 'bw5|w3': {'w3|ad0': 60, 'w3|j0': 40}, 'w3|ad0': {'ad0|bp8': 80}, 'ad0|bp8': {'#Z#': 100}, 'w3|j0': {'j0|cn2': 40}, 'j0|cn2': {'#Z#': 40}, 'bw5|ao1': {'ao1|ad0': 20}, 'ao1|ad0': {'ad0|bp8': 20}, 'an0|aj6': {'aj6|w3': 20}, 'aj6|w3': {'w3|ad0': 20}}
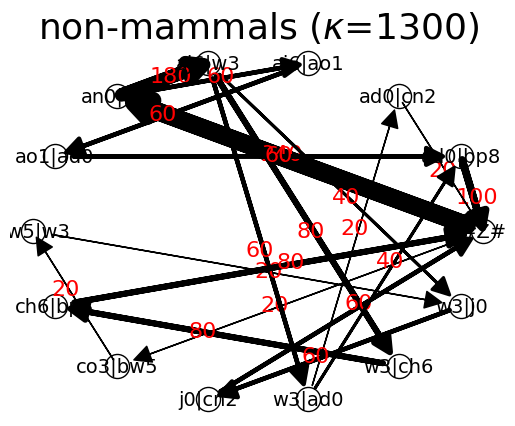
non-mammals : {'#Z#': {'an0|aj6': 240, 'co3|bw5': 20}, 'an0|aj6': {'aj6|w3': 180, 'aj6|ao1': 60}, 'aj6|w3': {'w3|ad0': 60, 'w3|j0': 40, 'w3|ch6': 80}, 'w3|ad0': {'ad0|cn2': 20, 'ad0|bp8': 40}, 'ad0|cn2': {'#Z#': 20}, 'w3|j0': {'j0|cn2': 60}, 'j0|cn2': {'#Z#': 60}, 'w3|ch6': {'ch6|bp8': 80}, 'ch6|bp8': {'#Z#': 80}, 'ad0|bp8': {'#Z#': 100}, 'aj6|ao1': {'ao1|ad0': 60}, 'ao1|ad0': {'ad0|bp8': 60}, 'co3|bw5': {'bw5|w3': 20}, 'bw5|w3': {'w3|j0': 20}}
prediction = ([np.str_('mammals'), np.str_('non-mammals'), np.str_('non-mammals'), np.str_('mammals'), np.str_('non-mammals'), np.str_('non-mammals'), np.str_('mammals'), np.str_('non-mammals'), np.str_('mammals'), np.str_('mammals'), np.str_('non-mammals'), np.str_('non-mammals'), np.str_('mammals'), np.str_('non-mammals'), np.str_('non-mammals'), np.str_('non-mammals'), np.str_('non-mammals'), np.str_('non-mammals'), np.str_('mammals'), np.str_('non-mammals')], [0.7525988740957668, 0.7374730387072518, 0.6481206209700475, 0.6920434112665808, 0.8441468861635344, 0.5540675820478976, 0.6868684713085881, 0.6602610945413664, 0.7525988740957668, 0.6920434112665808, 0.8441468861635344, 0.8441468861635344, 0.7525988740957668, 0.6481206209700475, 0.8441468861635344, 0.5540675820478976, 0.5540675820478976, 0.6602610945413664, 0.6920434112665808, 0.6602610945413664])
true y = ['mammals' 'non-mammals' 'non-mammals' 'mammals' 'non-mammals'
'non-mammals' 'mammals' 'non-mammals' 'mammals' 'non-mammals'
'non-mammals' 'non-mammals' 'mammals' 'non-mammals' 'non-mammals'
'non-mammals' 'mammals' 'non-mammals' 'mammals' 'non-mammals']
trajectory for non-mammals :
['Give Birth:no', 'Lay Eggs:yes', 'Can Fly:no', 'Live in Water:no', 'Have Legs:no']
If you want to see the detail what is inside the code of the chart, you can call the look up table
[4]:
tp.lut
[4]:
{'co3': 'Give Birth:yes',
'bw5': 'Lay Eggs:no',
'w3': 'Can Fly:no',
'ad0': 'Live in Water:no',
'bp8': 'Have Legs:yes',
'an0': 'Give Birth:no',
'aj6': 'Lay Eggs:yes',
'cn2': 'Have Legs:no',
'j0': 'Live in Water:yes',
'ch6': 'Live in Water:sometimes',
'ao1': 'Can Fly:yes'}
Or, you can also see the inverse look up table, whichever more convinience for you
[5]:
tp.inv_lut
[5]:
{'Give Birth:yes': 'co3',
'Lay Eggs:no': 'bw5',
'Can Fly:no': 'w3',
'Live in Water:no': 'ad0',
'Have Legs:yes': 'bp8',
'Give Birth:no': 'an0',
'Lay Eggs:yes': 'aj6',
'Have Legs:no': 'cn2',
'Live in Water:yes': 'j0',
'Live in Water:sometimes': 'ch6',
'Can Fly:yes': 'ao1'}
Transportation Mode Choice
Transportation mode choice is a critical component of travel behavior. It involves the selection of a transportation mode.
In the example below, we will break down the detail and slower than the above.
Instead of typing your data, you can also have your data table in CSV format. You can load your own data file using the following function.
[ ]:
# define the class
tp = ift.Table_Classifier(markovOrder=1,name="Transportation Mode")
# change this into your own folder data path
folder=r"C:\Users\Kardi\Documents\Kardi\Personal\Tutorial\NetworkScience\IdealFlow\Software\Python\Data Science\ReusableData\Supervised"
fName='TransportationMode.csv'
file_name = os.path.join(folder, fName) # Join the paths
# print('file_name:',file_name)
# Read the data
table_data = tp.read_csv(file_name)
print('table_data"\n',table_data)
table_data"
[['Gender', 'CarOwnership', 'TravelCost', 'IncomeLevel', 'TransportationMode'], ['Male', '0', 'Cheap', 'Low', 'Bus'], ['Male', '1', 'Cheap', 'Medium', 'Bus'], ['Female', '0', 'Cheap', 'Low', 'Bus'], ['Male', '1', 'Cheap', 'Medium', 'Bus'], ['Female', '1', 'Cheap', 'Medium', 'Train'], ['Male', '0', 'Standard', 'Medium', 'Train'], ['Female', '1', 'Standard', 'Medium', 'Train'], ['Female', '1', 'Expensive', 'High', 'Car'], ['Male', '2', 'Expensive', 'Medium', 'Car'], ['Female', '2', 'Expensive', 'High', 'Car']]
We will show how the input (X) and output (y) is extracted from data table.
First, it extracts the first row (variable names)
Next, extract X (features) not including the label
Then, extract y (labels)
Finally, combine the variable and value as one string to represent a node in IFN.
[7]:
# Extract the first row (variable names)
variable_names = table_data[0][:-1]
variable_names
[7]:
['Gender', 'CarOwnership', 'TravelCost', 'IncomeLevel']
[8]:
# Extract X (features) not include label
X = [row[:-1] for row in table_data[1:]]
X
[8]:
[['Male', '0', 'Cheap', 'Low'],
['Male', '1', 'Cheap', 'Medium'],
['Female', '0', 'Cheap', 'Low'],
['Male', '1', 'Cheap', 'Medium'],
['Female', '1', 'Cheap', 'Medium'],
['Male', '0', 'Standard', 'Medium'],
['Female', '1', 'Standard', 'Medium'],
['Female', '1', 'Expensive', 'High'],
['Male', '2', 'Expensive', 'Medium'],
['Female', '2', 'Expensive', 'High']]
[9]:
# Extract y (labels)
y = [row[-1] for row in table_data[1:]]
y
[9]:
['Bus', 'Bus', 'Bus', 'Bus', 'Train', 'Train', 'Train', 'Car', 'Car', 'Car']
Since the values of a variable can be the same name across different variables (e.g. ‘Give Birth:yes’ is not equal to ‘Have Legs:yes’), we need to include variable name into the value (Variable:Value). This step is done by the prepare_data_table method.
[10]:
X, y = tp.prepare_data_table(table_data)
X
[10]:
[['Gender:Male', 'CarOwnership:0', 'TravelCost:Cheap', 'IncomeLevel:Low'],
['Gender:Male', 'CarOwnership:1', 'TravelCost:Cheap', 'IncomeLevel:Medium'],
['Gender:Female', 'CarOwnership:0', 'TravelCost:Cheap', 'IncomeLevel:Low'],
['Gender:Male', 'CarOwnership:1', 'TravelCost:Cheap', 'IncomeLevel:Medium'],
['Gender:Female', 'CarOwnership:1', 'TravelCost:Cheap', 'IncomeLevel:Medium'],
['Gender:Male',
'CarOwnership:0',
'TravelCost:Standard',
'IncomeLevel:Medium'],
['Gender:Female',
'CarOwnership:1',
'TravelCost:Standard',
'IncomeLevel:Medium'],
['Gender:Female',
'CarOwnership:1',
'TravelCost:Expensive',
'IncomeLevel:High'],
['Gender:Male',
'CarOwnership:2',
'TravelCost:Expensive',
'IncomeLevel:Medium'],
['Gender:Female',
'CarOwnership:2',
'TravelCost:Expensive',
'IncomeLevel:High']]
The output part (y) is just an array of the category label values from the table data
[11]:
y
[11]:
array(['Bus', 'Bus', 'Bus', 'Bus', 'Train', 'Train', 'Train', 'Car',
'Car', 'Car'], dtype='<U18')
Trainig the data table is using fit method.
[12]:
accuracy = tp.fit(X, y)
print("Accuracy:", accuracy)
Accuracy: 1.0
Once you train the model, there are several IFNs. The name of each IFN is shown below.
[13]:
tp.IFNs
[13]:
{np.str_('Bus'): Bus, np.str_('Train'): Train, np.str_('Car'): Car}
The look up table is useful to see what is inside the IFN. We use hash code to represent Variable:Value uniquely.
[14]:
print("LUT:\n", tp.lut)
LUT:
{'ag3': 'Gender:Male', 'ce3': 'CarOwnership:0', 'ad0': 'TravelCost:Cheap', 'au7': 'IncomeLevel:Low', 'cl0': 'CarOwnership:1', 'bg9': 'IncomeLevel:Medium', 'cf4': 'Gender:Female', 'ar4': 'TravelCost:Standard', 'bk3': 'TravelCost:Expensive', 'bv4': 'IncomeLevel:High', 'bc5': 'CarOwnership:2'}
To show the IFN for each category
[15]:
for name,ifn in tp.IFNs.items():
print(name,':\n',ifn)
ifn.show(layout="Circular")
Bus :
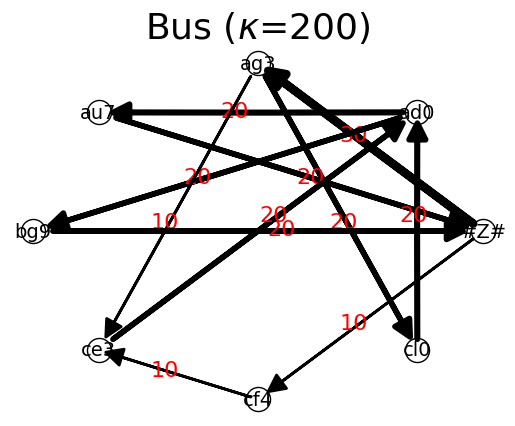
{'#Z#': {'ag3': 30, 'cf4': 10}, 'ag3': {'ce3': 10, 'cl0': 20}, 'ce3': {'ad0': 20}, 'ad0': {'au7': 20, 'bg9': 20}, 'au7': {'#Z#': 20}, 'cl0': {'ad0': 20}, 'bg9': {'#Z#': 20}, 'cf4': {'ce3': 10}}
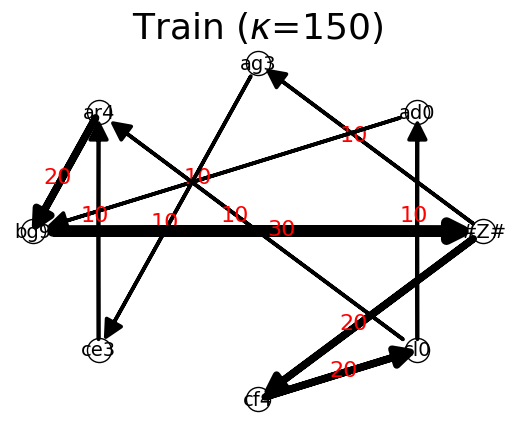
Train :
{'#Z#': {'cf4': 20, 'ag3': 10}, 'cf4': {'cl0': 20}, 'cl0': {'ad0': 10, 'ar4': 10}, 'ad0': {'bg9': 10}, 'bg9': {'#Z#': 30}, 'ag3': {'ce3': 10}, 'ce3': {'ar4': 10}, 'ar4': {'bg9': 20}}
Car :
{'#Z#': {'cf4': 20, 'ag3': 10}, 'cf4': {'cl0': 10, 'bc5': 10}, 'cl0': {'bk3': 10}, 'bk3': {'bv4': 20, 'bg9': 10}, 'bv4': {'#Z#': 20}, 'ag3': {'bc5': 10}, 'bc5': {'bk3': 20}, 'bg9': {'#Z#': 10}}
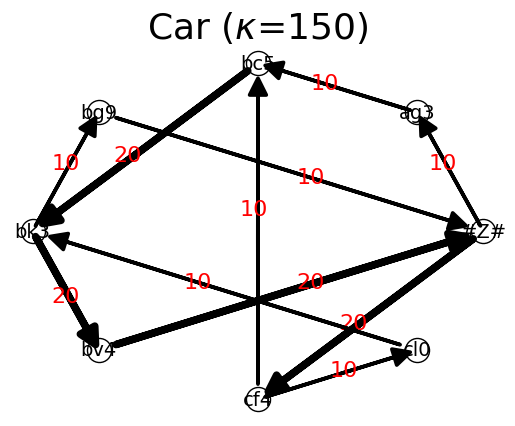
Prediction
Once the model is calibrated, we can now predict back from the input data.
[16]:
print("\nprediction =",tp.predict_table(X),'\n','\ntrue y =',y,'\n')
prediction = ([np.str_('Bus'), np.str_('Bus'), np.str_('Bus'), np.str_('Bus'), np.str_('Train'), np.str_('Train'), np.str_('Train'), np.str_('Car'), np.str_('Car'), np.str_('Car')], [0.6750483087451477, 0.49609720217760167, 0.648279853472202, 0.49609720217760167, 0.4535373600380496, 0.5246693416824478, 0.5644074501213597, 0.6294248059480595, 0.4934139346435913, 0.749974691428685])
true y = ['Bus' 'Bus' 'Bus' 'Bus' 'Train' 'Train' 'Train' 'Car' 'Car' 'Car']
Random Generation of Data
IFN is a generative grapical model. You can random generate back the input data for the given output label. Thus, generative is is an inverse function of the prediction from the data. Knowing the class category output, get back the possible random input.
[17]:
import random
category=random.choice(y)
tr=tp.generate(category)
print('trajectory for',category,":\n",tr)
trajectory for Bus :
['Gender:Female', 'CarOwnership:0', 'TravelCost:Cheap', 'IncomeLevel:Low']
I hope you enjoy this simple tutorial.