
Click here to purchase the complete E-book of this tutorial
Second Iteration
In the second iteration, we need to update our data table. Since Expensive and Standard Travel cost/km have been associated with pure class, we do not need these data any longer. For second iteration, our data table D is only come from the Cheap Travel cost/km. We remove attribute travel cost/km from the data because they are equal and redundant.
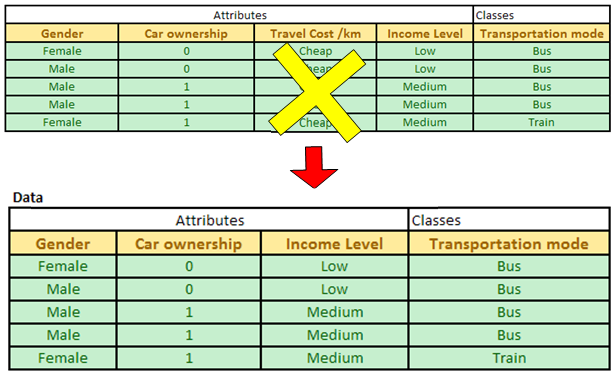
Now we have only three attributes: Gender, car ownership and Income level. The degree of impurity of the data table D is shown in the picture below.
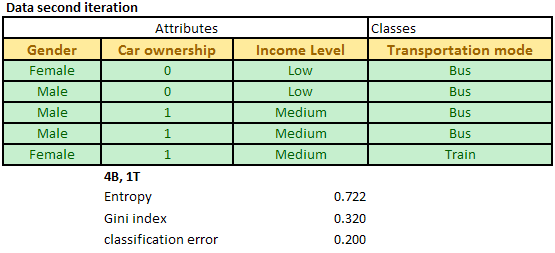
Then, we repeat the procedure of computing degree of impurity and information gain for the three attributes. The results of computation are exhibited below.

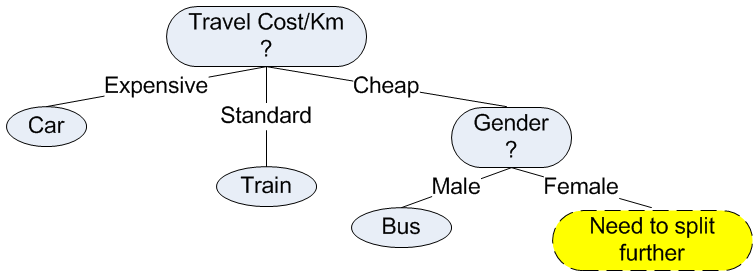
The maximum gain is obtained for the optimum attribute Gender. Once we obtain the optimum attribute, the data table is split according to that optimum attribute. In our case, Male Gender is only associated with pure class Bus, while Female still need further split of attribute.

Using this information, we can now update our decision tree. We can add node Gender which has two values of male and female. The pure class is related to leaf node, thus Male gender has leaf node of Bus. For Female gender, we need to split further the attributes in the next iteration.
Third iteration
Data table of the third iteration comes only from part of the data table of the second iteration with male gender removed (thus only female part). Since attribute Gender has been used in the decision tree, we can remove the attribute and focus only on the remaining two attributes: Car ownership and Income level.

If you observed the data table of the third iteration, it consists only two rows. Each row has distinct values. If we use attribute car ownership, we will get pure class for each of its value. Similarly, attribute income level will also give pure class for each value. Therefore, we can use either one of the two attributes. Suppose we select attribute car ownership, we can update our decision tree into the final version

Now we have grown the final full decision tree based on the data.
Click here to purchase the complete E-book of this tutorial
This tutorial is copyrighted .
Preferable reference for this tutorial is
Teknomo, Kardi. (2009) Tutorial on Decision Tree. http://people.revoledu.com/kardi/tutorial/DecisionTree/