
<
Previous
|
Next
|
Contents
>
Read this tutorial comfortably off-line. Click here to purchase the complete E-book of this tutorial
Modeling Environment
Suppose we have 5 rooms in a building connected by certain doors as shown in the figure below. We give name to each room A to E. We can consider outside of the building as one big room to cover the building, and name it as F. Notice that there are two doors lead to the building from F, that is through room B and room E.
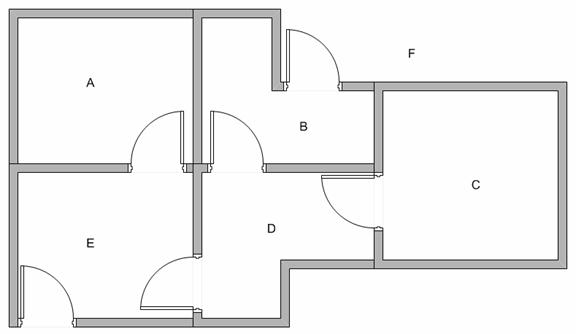
We can represent the rooms by graph, each room as a vertex (or node) and each door as an edge (or link).
Refer to my other tutorial on Graph if you are not sure about what is Graph
.
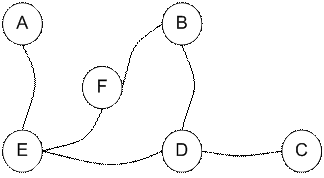
We want to set the target room. If we put an agent in any room, we want the agent to go outside the building. In other word, the goal room is the node F. To set this kind of goal, we introduce give a kind of reward value to each door (i.e. edge of the graph). The doors that lead immediately to the goal have instant reward of 100 (see diagram below, they have red arrows). Other doors that do not have direct connection to the target room have zero reward. Because the door is two way (from A can go to E and from E can go back to A), we assign two arrows to each room of the previous graph. Each arrow contains an instant reward value. The graph becomes state diagram as shown below
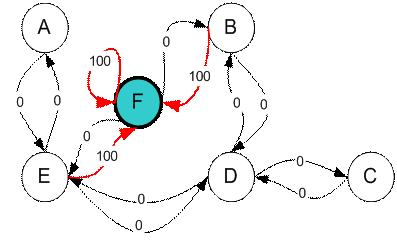
Additional loop with highest reward (100) is given to the goal room (F back to F) so that if the agent arrives at the goal, the agent will remain there forever. This type of goal is called absorbing goal because when it reaches the goal state, it will stay in the goal state.
Tired of ads? Read it off line on any device. Click here to purchase the complete E-book of this tutorial
<
Previous
|
Next
|
Contents
>
Preferable reference for this tutorial is
Teknomo, Kardi. 2005. Q-Learning by Examples. http://people.revoledu.com/kardi/tutorial/ReinforcementLearning/index.html